SIGCOMM22 论文分享 | LiveNet: a low-latency video transport network for large-scale live streaming

本期分享SIGCOMM22主机网络和视频传输专题下的论文:LiveNet: a low-latency video transport network for large-scale live streaming。该文作者来自中国科学院大学和阿里巴巴集团。
1. 动机和背景
随着全球新冠疫情的肆虐,实时视频传输在我们日常生活中已必不可少。与此同时,在线视频购物、在线视频会议在这两年的受众不断增多,具有较低端到端延迟的直播方案因此备受重视。本文基于此需求,力求减少直播中的端到端延迟,即减少从直播者采集到一个视频帧到该视频帧在观众客户端上被渲染所经历的时间。
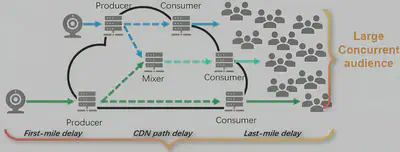
对于在线购物而言,作者认为理想的端到端延迟应该小于1秒。如图一所示,端到端延迟又包括了四部分:第一公里延迟、CDN延迟、最后一公里延迟、缓存延迟。其对应的说明如下:
- 第一公里延迟:直播者采集一个视频帧并将其编解码的延迟、推到CDN网络的接入点(称为CDN生产者)的传输延迟,这一部分通常为150ms。
- 最后一公里延迟:观看者从CDN网络的接入点(称为CDN消费者)拉取一个视频帧的传输延迟,加上解码渲染到屏幕的延迟。这一部分通常为150ms。
- 缓存延迟:为了避免网络环境抖动造成观众观看视频时的卡顿,通常在观众的客户端内缓存一定的视频帧,该视频帧的播放时长为300ms。
- CDN延迟:该延迟是指CDN网络从CDN生产者接收到视频帧之后,经过转解码和CDN网络内部的传输处理之后转发到CDN消费者所经历的延迟。在端到端延迟为1s的约束下,减去上面三部分的总和,该部分延迟一般要求小于300ms。
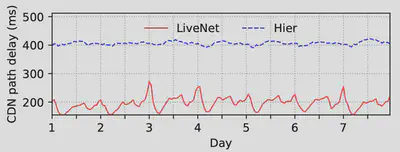
作者在阿里巴巴工作时,观察到目前阿里的CDN网络架构无法满足300ms的CDN延迟要求。如图二所示,蓝色线条为阿里巴巴的CDN架构的平均传输延迟。一周的观测结果表明:该部分延迟通常400ms左右,超过了直播对CDN延迟的300ms的最低要求。因此,本文的目标是改进阿里的CDN的架构,以降低直播时的端到端延迟。
2 问题引入
作者为了降低直播时的端到端延迟,尝试在两方面优化以期达到理想效果。这两方面分别是:CDN架构和CDN节点的报文转发和处理逻辑。
2.1 传统CDN架构的问题
作者认为,阿里的基于分层的CDN架构(称为HIER)并不适合于传输对实时性有严格要求的视频流。如图三所示,HIER包含了一个统一的视频流处理中心,该部分负责处理所有视频流(比如视频编解码)以及管理其他CDN节点。CDN节点,在逻辑上分为了两层,它们负责转发视频流内容,但不处理视频流内容。因此,当一个节点收到直播者推送的视频流数据之后,需要先从L1层转发到L2层,直到根部的视频流处理中心。最后再以反方向的逻辑转发给视频流的观看者。这样一来一回将会经过五个节点。
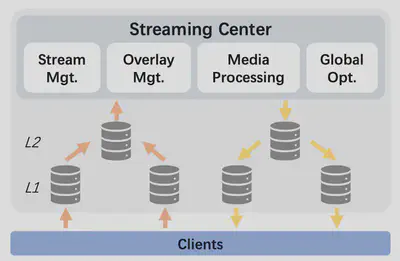
因此HIER存在的问题如下:
- 经过的CDN节点太多,报文每转发一次都要消耗一定的时间,在时间上造成了大的开销。
- 上层节点是逐渐减少的,当底层的多个结点同时需要传输视频流,并且它们逻辑上和同一个高层节点相连接时,这会造成高层节点的过载,最终导致服务质量下降。
- 这样树形的CDN网络很难被扩展,灵活性比较低。
因此, 作者希望改进这种树形的CDN架构,将其扁平化。例如能否通过某种方式,将一个CDN生产者接收到的数据直接经过一个或者两个中转节点转发到CDN消费者节点,中间经过的路径尽可能的被减短。
2.2 报文转发处理逻辑的问题
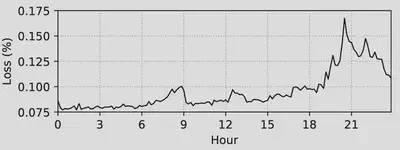
数据中心网络的节点与节点之间使用专网,这样的网络具有带宽高、丢包率低的特点。因此使用传统的TCP传输协议,报文不可避免的需要经过内核态的拥塞控制、流量控制等复杂逻辑,这也会带来一定的开销,对于实时性的数据传输并不友好。如图四所示,作者在阿里巴巴工作时,观察到网络丢包率最高也只有百分之0.175。基于此事实,作者认为CDN节点应该避免将报文经TCP协议栈传输,而应该直接转发,同时也应该设计一种补偿机制,在报文丢失的情况下再对其进行重传。
3 关键技术
针对上面两个问题,下文就作者的解决方案进行介绍。
3.1 扁平化的CDN架构
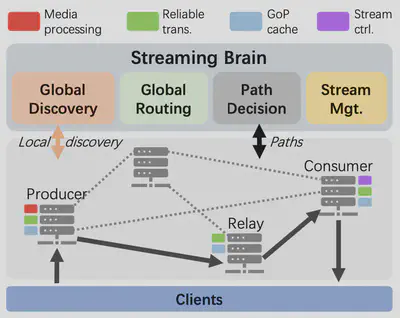
如图五所示,作者将所有的CDN节点分为了四种,分别为:
- CDN生产者节点:在直播者发起直播请求之后,通过DNS重定向到CDN生产者节点。用以从直播者接受视频帧,必要时对视频帧进行转码。
- CDN消费者节点:接收观众的观看请求,
- 如果该请求是一个该CDN节点不知道的视频流ID,该CDN节点首先向中心节点(即图中的Streaming Brain)查询通往CDN生产者的路径,然后建立路径之后传输视频流。
- 如果该请求是一个该CDN节点已知的视频流ID,则直接转发属于该视频流的视频帧到观众。
- 中继节点:中继节点负责接收来着CDN生产者的视频帧,并缓存到本地。另外有了中继节点可以建立自CDN生产者到CDN消费者节点的多条路径。
- 控制平面节点:即图中的Streaming Brain,是一个整体的控制平面逻辑,又包括三个组件:
- 全局发现组件:收集所有CDN节点的状态信息,包括与之关联链路的负载、CDN节点本身的负载。
- 路径决定组件:负责接收来自客户端的路径查询请求,并返回路径。另外,当CDN生产者节点收到一个直播流,要向该组件注册,注册的数据为:<生产者节点ID,视频流ID>。
- 全局路由组件:根据收到的CDN节点的状态信息,计算每对节点之间的路径。更新路径到路径决定组件的路径表中。
3.2 扁平化的CDN节点工作流
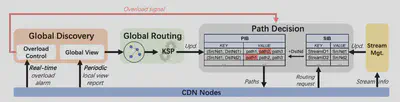
以下就上图介绍该扁平化的CDN节点的工作流和其实现方法:
3.2.1 路由表建立流程
- 每一个CDN节点定期更新该节点的负载信息到全局发现组件(一分钟一次)。另外,当任何一个节点负载达到一个阈值时,会立刻通知到全局发现组件。
- 全局路由组件收到来自全局发现组件的负载信息之后,形成一个类似网状的图,相连接的节点之间都有权重值,权重值的计算主要综合考虑一个CDN节点的负载情况、一个链路的丢包率、传输往返延迟、链路的负载情况,具体计算过程可参考论文,篇幅所限此处不再展开。然后通过KSP(最短路径算法)算法计算每一对节点之间的最短路径,随后将其更新到路径决定组件的路径表中,即PIB。另外该KSP算法会保证该路径中间的跳数少于两个节点,以避免报文转发时经过太长的路径导致CDN延迟增高。
- 路径表一旦收到一个过载信号,与该过载链路或过载节点相关的路径将会被作废。
3.2.2 直播流工作流程
-
当生产者CDN节点收到一个直播流的请求,首先会向路径决定组件注册该流,如路径决定组件中的 SIB表所示,注册的信息为<视频流ID,CDN生产者节点ID>二元组。然后接收来自客户端的视频帧,并根据本地的转发表转发该视频流。
-
客户端向CDN生产者节点发起一个视频流的请求并附上相应的视频流ID。
-
CDN消费者节点接收到该视频流请求之后,如果该请求是一个该CDN节点未知的视频流ID,该CDN节点首先向中心节点(即图六的路径决策组件)查询通往CDN生产者的路径,在建立路径之后才能够传输该视频流。
-
假设该CDN消费者节点第一次收到对该视频流ID的请求,向路径决定模块发起查询,提交视频流ID号和其节点号DstNdID。
-
路径决策组件收到该视频流ID号和DstNdID后,用视频流ID号在SIB表中查询对应的SrcNDID。接着,使用SrcNDID和DstNDID从PIB表中查询相应的三个候选路径<path1,path2,path3>,最后交付给CDN消费者节点。
-
CDN消费者节点收到三个候选路径<path1,path2,path3>后, 根据自己的偏好策略从中选择一条路径。假如选择的路径为path1,其包含的节点为<生产者节点,中转节点1,中转节点2,消费者节点>。消费者节点向中转节点2发送视频流ID和path1路径<生产者节点,中转节点1,中转节点2,消费者节点>。
-
中转节点2将在本地注册转发表,表项为<StreamID, 消费者节点>,译为将与StreamID相关的视频流帧转发到下一跳节点,即消费者节点。
-
中转节点2重复CDN消费者节点的动作,向它的前一个节点(即中转节点1)转发StreamID和path1。直到达到根部的生产者节点。
-
path1上的所有节点的转发表项建立完成之后,每一个节点收到与StreamID相关的视频帧之后,将会根据转发表项,转发到下一个节点。
3.3 优化报文转发和处理逻辑
传统的数据中心网络使用TCP传输数据,内核态的处理逻辑太复杂,导致报文转发的迟滞。因此作者改用RTP协议结合RTCP来做,并提出了快慢路的概念。其中RTP协议用来转发数据,一旦一个节点收到一个报文,立刻将其转发到下一个节点,个人理解这是借助了RTP协议的优势:
- 基于UDP可以直接转发,不需要经过TCP相应的复杂逻辑。
- 尽管RTP协议并不是可靠的,但提供了有序的保障,会为每一个报文标序号,并在接收方重组(因为不可靠可能出现空缺)。
RTCP协议又提供了相应的控制逻辑,接收方会将最近的丢包情况以50ms的粒度反馈给发送方,发送方据此调整其发送速率,同时将丢失的报文重发到接收方。
整体的逻辑如图七所示,此处就该图对快慢路的主要逻辑做介绍:
绿色部分:慢路
- 接收控制逻辑:CDN节点的快路收到一个报文之后,在将其通过快路再次立即转发出去的。同时,本地留一备份到慢路上,以在丢失的时候重传。
- 发送控制逻辑:该逻辑会接收下游节点在快路上的丢包信息,并调整速率并反馈到快路上,同时将丢失的报文(这就是上面备份的意义)通过快路快速转发出去,重传的报文优先放在快路的转发队列前。
黄色部分:快路
-
每收到一个报文,将其放入本地的发送队列中。
-
报文发送器(pacer)负责将报文按照速率的要求,以相应的频率从队列中取报文并发出。
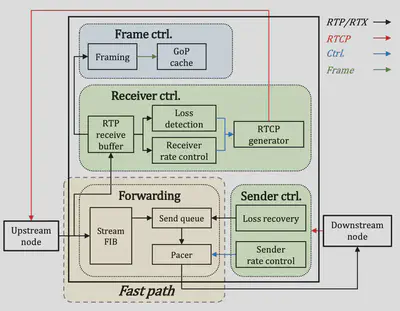
需要注意快慢路本质上是一种逻辑上的概念,作者将其抽象,控制逻辑为慢路,其负责可靠性。转发逻辑为快路,其负责快速的转发报文,并绕开TCP协议栈。
4 实验结果
作者在实验结果部分将所提出的工作(即LiveNet)和先前的HIER做了对比,主要关注了以下指标:
- CDN内部延迟:一个视频帧到CDN生产者,传输到CDN消费者所经历的延迟。
- 端到端延迟:直播者到观看者之间整体的视频流延迟。
- 卡顿率:用户在观看视频时,使用LiveNet和HIER在观看期间经历卡顿的概率。
- 快速启动率:从观看者点击一个直播视频开始计时,到接收到第一个视频帧的时间是否低于一秒,低于一秒,为快速启动。
接下来对作者的实验结果做一些介绍:
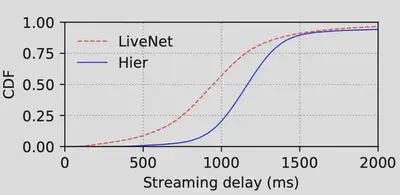
首先看图二,为期一周的测量结果表明,LiveNet(蓝色部分)相比HIER(红色部分)大幅度降低了CDN内部延迟,从平均的400ms延迟降低到了200ms左右。另外根据图八的CDF图所示,百分之五十以上的视频流在经过LiveNet传输时,端到端延迟都能满足在一秒以下,而HIER只有不到百分之二十五的视频流满足此要求。
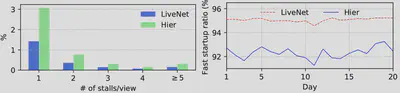
接着看图九,作者分别对卡顿率和快速启动率做了测量。在卡顿率指标上,用户观看视频时经历的卡顿次数(1、2、3、4、>=5)的概率相比HIER都有了显著的降低。另外在快速启动率指标上,LiveNet能够保证百分之九十五左右的快速启动率。作为对比,HIER只有百分之九十二左右。
5 个人总结
本文作者针对阿里传统的层次型CDN架构所存在的问题,将节点和节点之间的路径转化成扁平的形式,带来的最明显的好处就是能够有效的减小CDN内部报文转发延迟。另外快慢路本质上是一种逻辑上的抽象,快路本质上是转发逻辑,负责报文的快速转发,绕开了TCP的复杂处理逻辑;而慢路本质上是控制逻辑,负责调整发送速率和重传报文。因此作者采用了RTCP和RTP协议来替代以往的RTMP协议,这本质上是一种工程上的考量,目的是为了解决现在的直播系统存在的问题——为了端到端延迟而服务。