SIGCOMM22 论文分享 | Starvation in End-to-End Congestion Control

今天分享的是来自MIT的Venkat Arun,Mohammad Alizadeh和Hari Balakrishnan三位学者发表在SIGCOMM的一篇论文。论文讨论了基于延迟的拥塞控制算法存在着极度不公平现象,从算法的机理出发进行说明,具有较强的理论性。同时这篇论文也是SIGCOMM22的最佳论文。
动机与背景
随着目前视频以及交互式应用的不断发展,用户对低时延的需求越来越迫切。为了保证传输层的服务质量,基于时延的拥塞控制应运而生,例如BBR、Copa以及PCC等算法。这些拥塞控制算法主要为了在防止引入排队时延的情况下,实现链路的高利用率。但是,该论文发现当共享瓶颈链路的多条流使用同一种基于时延的拥塞控制算法时,存在某些流饿死现象——一种带宽分配的极度不公平现象。
问题引入
1. 延迟收敛现象
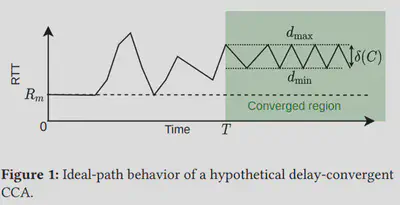
作者提出诸如BBR、Copa以及PCC等基于延迟的拥塞控制算法均存在一种延迟收敛现象。延迟收敛是指当算法稳定后,发送方与接收方之间的端到端延迟稳定在一个固定区间内,区间上边界记作dmax,下边界记作dmin,区间长度记作δ(C)。
2. 非拥塞延迟
作者指出当前端到端延迟一共包含三个主要部分:传播延迟(常数)、拥塞延迟(排队延迟)以及非拥塞延迟。wifi的延迟应答、内核对数据包的处理延迟以及发送方/接收方的突发传输/应答等机制均会带来非拥塞延迟。通过上述非拥塞延迟的举例可以看出非拥塞延迟是一个随机值,和稳定后的拥塞延迟一样处在一个固定区间内波动。由于拥塞延迟和非拥塞延迟行为相似因此很难加以区分。作者将非拥塞延迟的波动区间记作D。
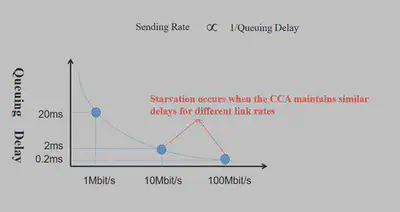
3. 饿死现象
Copa拥塞控制算法族的链路的发送速率与数据包排队延迟成反比关系,如下图所示。从图中可以看到当算法稳定时对排队时延的不同观测所导致的链路发送速率有着巨大差异。同时由于端对端延迟中非拥塞延迟的干扰,对排队时延的观测往往是不准确的,这种观测上的差异也就导致了数据流之间的发送速率出现较大差异,甚至发生饿死现象。
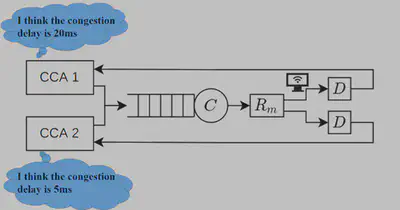
下图中有两条流共享同一个瓶颈链路,一条流记作流1使用CCA1拥塞控制算法同时该条数据链路使用的wifi接收方引入了一定的非拥塞控制延时,另一条流记作流2使用CCA2拥塞控制算法。流1因为存在非拥塞延迟的干扰过高估计了当前的排队时延,就导致流1会降低发送速率,造成不公平现象。
问题证明
1.两个定义
- f-高效的CCA
如果在具有瓶颈链路速率C和最小RTT RM的理想路径,拥塞控制算法(CCA)最终获得至少f C的吞吐量。
- CCA的s-公平性
从任意初始条件开始的两个流 f1 和 f2(例如,其中一个流可能运行了很长时间,而另一个流刚刚开始)。如果始终存在一个有限的时间 t,使得对于超过 t 的所有时间,较快的流与较慢的流实现的吞吐量之比小于 s,则网络是 s 公平的。
2.三步证明
作者通过Copa算法族引入了饿死现象,且认为所有基于时延的拥塞控制算法均存在这个现象,并通过以下三步进行证明。
1)假定数据流的延迟上限为dmax,下限为Rm。我们在[Rm,dmax]之间可以构造有限个长度为δmax,且彼此之间的距离为ε的排队延时族。同时定义这些波动的排队延时对应的带宽分别为λ0=λ,λ1…,且。根据鸽笼原理易得一定存在两个排队时延区间位于δmax+ε内。
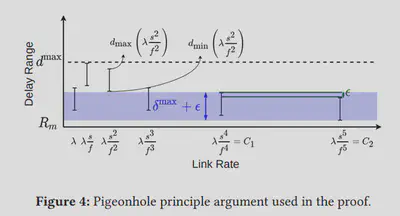
2)根据第一步的说明,可以构造两条独立的数据流,其分别具有带宽C1和C2(如图4)。可以构造两个CCA,其收敛后的排队时延记作d1(t),d2(t)差距小于ε且分别获取x1和x2的速率(如图5)。可以说明x2比x1的s倍还大。
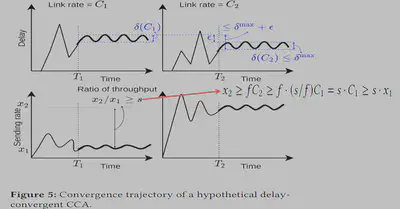
3)当两条流共享同一瓶颈链路时,假定将η1(t),η2(t)∈[0,D]记作两条链路的非拥塞延迟,d1(t),d2(t)记作两条链路的拥塞延迟。为了构造第二步的时延要求,我们需要控制η1(t),η2(t)使得η1(t)+d1(t)=d1(t)以及η2(t)+d2(t)=d2(t)。根据证明(具体见论文附件A),我们可以得到d*i(t)的表达式如下:
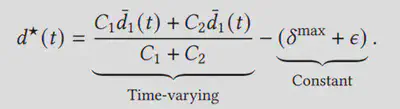
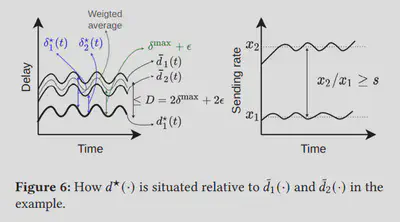
易得,d*i(t)具有以下两种性质:
d*i(t)<min{d*1(t),d*2(t)}
max{d*1(t),d*2(t)}<d*i(t)+D
根据以上两种性质我们知道可以获得 η*1(t),η*2(t)∈[0,D],使得当两条流共享瓶颈链路时存在 η*1(t)+d*1(t)=d1(t) 以及 η*2(t)+d*2(t)=d2(t) 的可能性。一旦发生这种现象,就出现饿死。
实验验证
针对上述理论证明作者给出了两个在模拟环境下的进行的实验进行说明理论证明的结果是正确的。
1. BBR
作者使用Mahimahi仿真平台上构造了两个共享同一瓶颈链路的BBR数据流,其传播时延分别是40ms和80ms,共享瓶颈链路的带宽是120Mbit/s。实验进行了60s的持续传输,最终出现一个流获得8.3Mbit/s,另一个获得107Mbit/s。

2. Copa
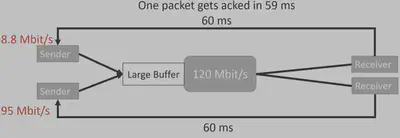
作者使用Mahimahi仿真平台上构造了两个共享同一瓶颈链路的Copa数据流,其传播时延均为60ms,共享瓶颈带宽为120Mbit/s。作者引入一个干扰使得其中一条流的时延估计为59ms,导致了其低估了传播时延也就意味着其之后均会高估排队时延,最终导致两条流的带宽分配为:8.8Mbit/s、95Mbit/s。
可行的解决方案
1. 故意的延迟震荡
根据上面的分析我们得到基于延时的拥塞控制算法产生饿死的根本原因在于其追求低延时即延迟收敛。但是基于丢包的拥塞控制算法采用AIMD的方式填充队列,并不会产生饿死现象。因此作者认为可以允许基于时延的拥塞控制算法像AIMD式的拥塞控制一样容忍更大的延迟波动来对抗非拥塞时延的干扰。
2. 显式拥塞信号,包括ECN等。
心得体会
本文以理论分析切入,从基于延时的拥塞控制算法的机理开始,发现这些算法最终导致自己违背了自己的初衷——公平性。文章的最后作者给出了几种针对饿死现象的解决方案,可以作为以后基于延时的拥塞控制的切入点。近年来,BBR以及Copa的大火,使得很多人认为基于丢包的算法已不具有竞争力。但从本论文的视角来看,基于延时的拥塞控制算法比如Copa,BBR等也存在着很大的不足,并不会导致基于丢包的拥塞控制算法退出历史舞台。