AI4Network团队在智能多路径QUIC协议方向工作被国际会议IEEE IWQoS2023录用

近日,AI4Network团队在多路径QUIC协议智能调度方面的工作“MARS: An Efficient Multi-agent DRL-based Scheduler for Multipath QUIC in Dynamic Networks”被第31届IEEE/ACM IWQoS 2023 (IEEE/ACM International Symposium on Quality of Service)国际会议录用。IWQoS是网络领域知名国际会议,专注于网络通信的服务质量领域,涵盖所有与QoS(服务质量)相关的最新理论和实验研究工作,长期以来一直是该领域受关注较高的国际会议,属于CCF(中国计算机学会)推荐的B类国际会议,会议录用率长期保持在**20%**左右。该工作作者为2021级硕士研究生韩雪强(第一作者),2023级博士研究生计晓岚,指导老师韩彪。
该工作聚焦解决当前多路径QUIC(MPQUIC)协议报文调度器在动态网络环境下无法满足多样化应用QoS需求的难点,提出使用多智能体强化学习框架对服务器端QUIC协议多条路径上的报文发送量进行分布式智能控制,结合多路径拥塞控制决策,在仿真和真实的动态网络环境下,实现了MPQUIC协议吞吐量、传输延迟等性能指标的明显提升,显著减少了乱序报文,降低了接收缓冲区开销。基于该工作团队已同步开发搭建了多路径QUIC协议传输系统,可支持文件、网页、视频、实时视频流、VR/AR等多种网络应用,为设计可移植高可靠的用户态多路径传输方案提供了参考思路。
动机与背景
随着视频流媒体、虚拟现实和增强现实等应用的深入发展,应用对底层传输网络的服务质量提出了更高的要求。多路径传输协议允许单个连接同时利用多个网络链路,如WiFi和LTE。多路径TCP协议(MPTCP)在2013年IETF工作组标准化。然而,MPTCP需要操作系统支持,阻碍了其大规模部署。快速UDP网络连接(Quick UDP Internet Connection, QUIC)协议深入发展,其多路径扩展,多路径QUIC协议(MPQUIC),作为MPTCP的替代方案被提出。MPQUIC作为一种用户空间协议,可以持续快速升级。
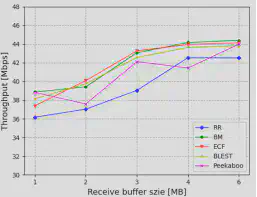
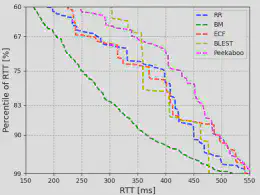
MPQUIC的关键问题之一是数据包调度。根据MPQUIC的大规模部署实验,其存在严重的队头阻塞问题:高延迟路径上调度的数据包到达时间晚于低延迟路径上的数据包,导致乱序数据包到达。由于队头(Head of Line, HoL)阻塞问题,接收端不得不分配较大内存来缓存乱序数据包。通过大量的预备实验分析,我们观测到接收方缓冲区的大小严重影响了MPQUIC的吞吐量性能(图1)。此外,随着实时视频流等应用的发展,应用迫切追求低延迟,而大多数的调度器仅针对特定应用需求设计。例如,基于强化学习(RL )的调度器 Peekaboo只关注最大化吞吐量,而不考虑数据包所经历的延迟。另一方面,bufferbloat-mitigation(BM)算法旨在降低缓存膨胀的影响以获得低延迟,但无法实现高吞吐量。多路径调度性能与应用需求仍有差距,如图2所示。
设计方案
针对上述问题,该工作提出使用多智能体强化学习的方法,结合多目标奖励函数来实现在动态网络环境下对应用多样化QoS需求的动态适应。
1.多智能体强化学习
1)为什么使用多智能体强化学习
从方法论的角度,我们将多路径调度视为一个决策问题,采用强化学习(RL)方法进行求解。与使用规则式策略的启发式方法不同,基于RL的调度器通过学习产生能够适应动态网络环境的数据包调度策略。之前的研究工作也考虑了将RL方法用于数据包调度问题:如Peekaboo使用在线RL算法生成调度策略,但收敛时间是在线方案的一个基本问题,并未得到很好解决;ReLeS探索了通过深度强化学习(DRL)方法来解决MPTCP中的调度问题,使用单智能体DRL为所有路径生成连接级控制策略。然而,当路径数量增加时,唯一的智能体学习最优调度策略的能力受限。因此在本工作中,我们应用多智能体强化学习(MADRL)方法对每条路径进行单独控制,以减轻单个智能体的负担,生成更优的策略。
2)设计框架
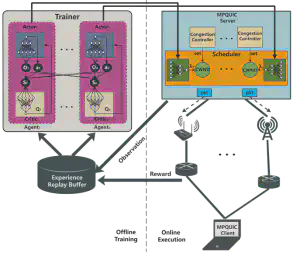
MARS框架如图3所示。MARS采用了MADDPG算法,一种多智能体和演员-评论家深度强化学习算法。在MARS中,每个智能体都有一个演员和评论家神经网络。我们采用异步训练算法,将数据收集和模型训练分离,以保证实时的数据包调度。因此,MARS框架主要由在线执行和离线训练两部分组成。
在线执行。在线执行过程中(图3右半部分),运行在发送端(服务器)的智能体感知网络环境,获取网络状态 $O_{i,t}$。然后,智能体将它们输入到执行器神经网络,该神经网络输出动作 $∏(O_{i,t})$。深度强化学习智能体面临的一个根本性挑战是解决探索与利用的困境。为了使智能体能够更好地探索未知环境,我们在演员神经网络生成的动作中加入衰减高斯噪声,可以表示为 $a_{i,t} = ∏(O_{i,t}) + N ( 0,σ_{i,t})$。智能体执行动作并得到结果奖励 $r_{i,t}$,然后转移到下一个新状态 $O_{i,t+1}$。为了有效地从经验中学习,智能体在一步转移中收集状态、动作和奖励,并将它们打包成一个元组 $<O_{i,t},O_{_i,t},a_{i,t},a_{_i,t},r_{i,t},O_{i,t+1},O_{i,t+1}>$,并将元组存储到经验回放缓冲区$D_i$中。
离线训练。在离线训练过程中(图3左图部分),智能体从经验回放缓冲区中采样,然后使用深度确定性策略梯度训练算法训练演员和评论家神经网络。每次训练后,MARS将训练好的演员神经网络与调度器进行同步,使其向最优策略移动。
2.多目标奖励函数设计
考虑具有n条路径(记N = { 1 , … , n })的多路径传输协议。它的网络资源有限,包括缓冲区和数据包等。这些资源被路径共享。在MARS中,每条路径都有一个带着独立奖励函数的深度强化学习智能体。对于传统的单智能体深度强化学习智能体,它自私地最大化自身奖励。但在MARS中,如果所有的智能体简单地最大化自己的奖励,并不能使多路径传输协议获得最大的性能。因此,我们将多路径传输协议调度问题看成一个一般和的n人博弈,其中每个智能体是一个玩家。我们通过设计利他奖励项,将利他行为引入到每个智能体中。这说明智能体并不是单纯最大化自身的性能,还关心其他路径的性能。它们相互竞争资源,同时为了获得更好的性能,它们合作将所有的数据传输到接收端。此外,在奖励函数的设计中,我们考虑了吞吐量、时延和乱序队列大小。智能体i的奖励函数记为:
$$ r_{i,t} = V^{th}-\beta V^{RTT} - \zeta V^{OFO} $$实验验证
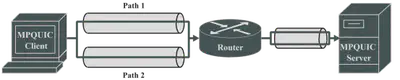
仿真实验采用如图4所示的网络拓扑结构。对于两条路径,我们分别设定了根据真实实验中的测量值选择的具体网络特征。采用32MB的文件下载应用程序进行性能评估。每个实验重复了20次。
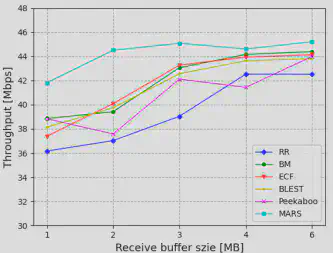
1.不同接收方缓冲区下的吞吐表现
图5展示了不同调度器在不同接收缓存大小下的聚合吞吐量。当接收缓存大小受限(<3MB)时,我们的调度器相比RR可以提高约16 %的吞吐量。当接收缓存足够大(≥3MB)时,没有HoL阻塞,因此6个调度器都能获得较好的带宽聚合效果。但是MARS的表现仍然优于其它调度器。
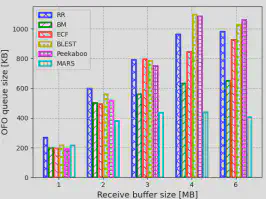
2.减少乱序数据包
我们使用乱序(OFO)队列大小作为度量。OFO队列规模越大,调度器性能越差。图 6给出了不同接收缓冲区大小下不同调度器的平均OFO队列大小。其他调度器在接收缓冲区大小有限的情况下可以保持较小的OFO队列大小,但随着接收缓冲区大小的增加,OFO 队列大小急剧增加。而MARS可以保持非常小的 OFO 队列大小,并且由于OFO队列大小的反馈,受接收缓冲区大小的影响较小。
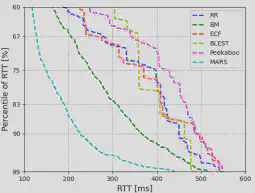
3.降低传输延迟
图7给出了RTT的百分位分布。从图7中我们可以观察到MARS比其他调度器实现了更小的RTT。这是因为与BM算法相比,MARS算法根据当前网络状态更加智能地做出决策,以降低数据包排队时延。同时,MARS充分利用快速路径来满足应用的低延迟需求。
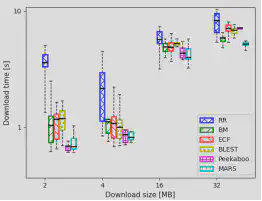
4.真实网络环境下的性能表现
通过评估不同调度器的下载时间来研究MARS在异构网络中的性能。我们 通过改变下载大小来模拟不同的流量类型。对于2MB的下载文件大小,MARS实现了与 Peekaboo相近的下载时间,但是与其他调度器相比,下载时间最低。然而,随着下载文件大小越来越大,MARS的优势更加明显。
总结
本工作提出了一种基于多智能体强化学习的 MPQUIC调度器 MARS,为适应不同接收端缓存大小和不同应用的QoS需求,MARS利用多智能体强化学习(MADRL) 技术在每条路径上独立生成数据包调度策略。同时,我们设计了一个多目标奖励函数来表征应用程序的QoS需求和乱序队列大小对协议性能的影响。我们在仿真和真实环境下评估了MARS,结果表明MARS的性能表现显著优于现有的多路径调度器。
该工作的源代码和原型系统将于近期发布,敬请关注。