MobiCom22 论文分享 | Real-time Neural Network Inference on Extremely WeakDevices: Agile Offloading with Explainable Al

今天分享是由两位来自Pittsburgh大学的两位学者发表在mobicom22上的一篇论文。该论文主要聚焦于解决当前在性能较弱的小型嵌入式设备上部署神经网络模型并进行实时推理的困难。文章提出了Agile NN——使用可解释神经网络与需要部署的神经网络模型进行协同离线训练,实现将原本需要在线推理的计算迁移到离线训练过程中,进而达到在小型嵌入式设备上部署并实现更加精确的实时神经网络推理。
研究动机
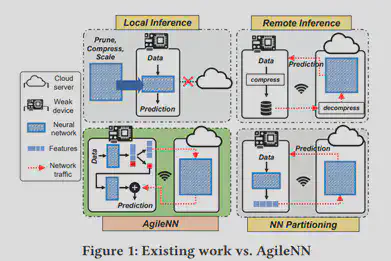
随着人脸识别、语音识别等深度学习模型与工业物联网的不断发展,在小型嵌入式设备上部署深度学习模型的需求迫切。但是小型嵌入式设备的内存以及计算能力较弱而深度学习模型的部署与实时推理需要大内存和强算力,因此如何在小型嵌入式设备上部署深度学习模型并进行实时推理成为一大难点。在以往的研究中,研究人员提出了三种解决方案。
1.本地推理(fig.1-topleft)
该方案通过对神经网络的权重和结构进行压缩和裁剪操作,减小部署以及运行模型的代价。但是该方案只能在诸如智能手机等具有较强性能的嵌入式设备上进行运行,一旦迁移到小型嵌入式设备上,由于神经网络压缩程度过高导致实时推理精确度下降。
2.远程推理(fig.1-topright)
该方案通过云端协同的方式,将嵌入式设备使用深度学习模型的负担迁移到云平台上,利用云服务器的强大性能减少了本地性能压力。但是为了实现云端协同的实时性,需要对神经网络的输入数据进行压缩,损失部分特征(甚至是及其重要的特征)。同时小型嵌入式设备为了节约电量的目的,仅仅使用低速的无线射频信号进行数据传输,导致本地数据需要较大时延传到云端,影响模型的实时性需求。
3.神经网络切分(fig.1-buttomright)
该方案在本地部署神经网络用于特征提取以及压缩,同时在云端部署推理神经网络模型。但是部署在本地的神经网络模型为了增强特征稀疏性引入了巨大的计算压力。
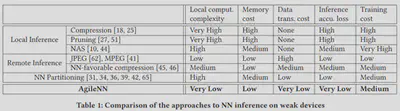
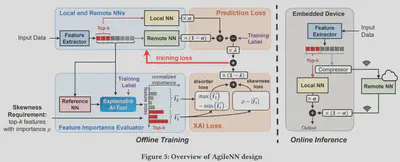
为了解决在嵌入式设备上部署实时推理模型的问题,该论文采用神经网络切分的结构,但是论文分析了以前采用神经网络切分中特征数据压缩的比例对云端实时推理的精确性和通信延迟的影响,得出结论:在神经网络切分的结构中通信延迟与实时推理的精确性具有互斥性。为了解决这个问题,本论文采用可解释神经网络方法例如梯度积分(IG),分析特征数据中对实时推理精确度较为重要的特征(记作top-k特征)保留在本地进行推断,而其余特征数据进行压缩传输到云端输入到神经网络推断模型中进行推理,将两个推理结果进行综合得到最终结果。整个系统离线训练与在线推理结构如fig.5所示,其中嵌入式设备上运行已经训练完成的可解释神经网络和本地经过压缩的实时推理模型,远程云端运行未经压缩的实时推理模型。
下面主要进行AgileNN离线训练部分介绍。AgileNN离线训练包含两个部分:可解释神经网络训练(论文中又称为特征提取器)和实时推理模型训练。但是可解释模型特征重要性评估的精确度依赖于实时推理模型的精确度,因此本论文在训练可解释神经网络模型时,选择了先预训练实时推理模型,在将可解释神经网络模型和实时推理模型进行协同训练。
1、可解释AI(因为可解释AI技术并不是该论文的主要创新点且论文的可解释AI算法是可被替换的,因此在此处不对可解释AI技术展开介绍,只对论文中如何使用可解释AI技术进行讲解)
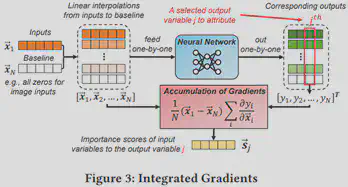
本文默认使用的可解释AI的技术为积分梯度法(IG),该方法旨在解释模型特征与预测结果之间的关系。由于IG广泛适用于任何可微分模型、易于实现且具有较高的计算效率因此被普遍使用。fig.3为IG方法分析图像分类器中输入图像像素特征重要性的流程。
1)特征重要性倾斜度(Skewness of feature Importance)保证
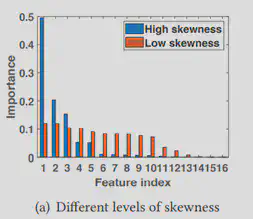
特征重要性倾斜度是指由特征提取器分析出的各个输入特征之间重要性差距大小,不同特征之间重要性差距越大代表特征重要性倾斜度越大(fig.4为实例)。在该模型中为了保证本地模型推理的精确性以及更大程度的压缩不重要特征属性保证低通信延迟,作者希望可解释AI工具输出的特征重要性分布差距越大越好。为了达到这个目的,在进行特征提取器训练时将重要性分布作为损失函数的一部分,记为,Lskewness。其中ρ代表top-k特征的重要性阈值。
$$ L_{skewness} = \max(0,\rho - |\overrightarrow{I_1}|) $$2)特征排序
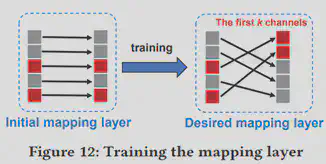
因为特征提取器在嵌入式设备中运行时,要确保top-k特征一定要对应设备的前k个输出管道(由于嵌入式设备硬件逻辑限制),因此在进行特征提取器离线训练时要确保特征按照重要性进行“非严格降序排列”(保证top-k的特征一定排在其他特征的前面)。作者将排序也作为特征提取器的损失函数的一部分。其中,I代表未排序的特征重要性向量,Isorted代表降序排序的特征重要性向量。
$$ L_{descent} = ||\overrightarrow{I} - \overrightarrow{I}_{sorted}||_2^2 $$2、实时推理模型
AgileNN的推理模型包括本地模型和远端模型两部分(fig1-buttomleft),分别用来处理top-k特征和其余不重要特征的推断。针对远端推断结果和本地推断结果进行加权相加。
$$ Result = LocalNN-R *α+RemoteNN-R*(1-α) $$关于α的确定,作者选择了sigmoid函数。其中,w和T均为超参数。
$$ \alpha(w;T) = \frac{1}{1+e^{-w/T}} $$实验验证
作者将模型部署在STM32F746上,并在四个数据集CIFAR10/100、SVHN、ImageNet-200上进行测试。实验模型部署细节如fig.14。
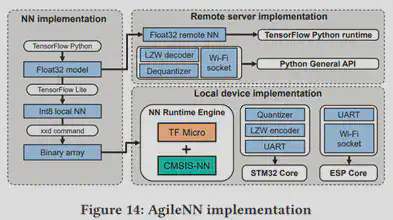
作者在数据集上与现有的4个算法进行了对比。根据fig.16,实验结果显示NgileNN有效减少了云端通信的延迟并且增加了实时推断的精确度。
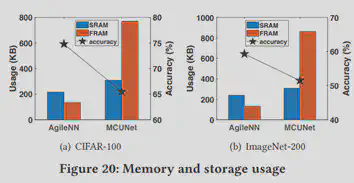
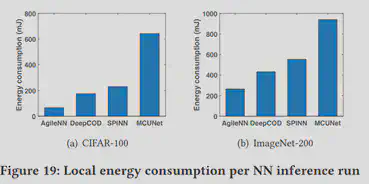
针对模型需要花费的部署以及运行开销,作者也进行了评估。根据fig.19可以看出AgileNN运行开销(以消耗的电量为基准)远低于其他模型。根据fig.20可以看到AgileNN在极少的内存占用的情况下实现了较高的推断准确性。
个人总结
该论文通过使用可解释AI技术有效地将深度学习实时推理模型的在线算力负载迁移到离线训练中,实现了在性能较弱的嵌入式设备中部署并运行深度学习模型同时保证了推理的精确度。论文向我们展示了可解释AI技术的应用,详细介绍了可解释AI的训练以及模型协同训练,可以作为可解释AI工程落地的参考。