SIGCOMM22 论文分享 | PLB: Congestion Signals are Simple and Effective for Network Load Balancing

今天给大家介绍的论文是由Google的研究团队提出的PLB——一种建立在传输协议和ECMP/WCMP之上,用于数据中心网络以减少网络热点的链路负载平衡设计。
一、背景介绍
当Google数据中心有未使用的容量时,拥塞热点会降低性能。热点是具有显著排队或丢包的拥塞交换机输出端口。而负载均衡问题一直都是一个值得广泛研究的问题,负载不均衡对数据中心网络的性能和效率都提出了挑战。
作者试图缓解Google数据中心上的拥塞问题时,发现无法应用已有的负载均衡的设计方案。这些方案是昂贵且耗时的,难以进行大规模部署。作者希望有一种负载均衡策略能够增量部署,以控制成本和可靠性风险。同时适应Google机群的异构性。因此作者提出了PLB这种简单有效的机制来满足以上需求,PLB利用了ipv6协议的支持,它只需要少量的传输配置更改,并可以与我们现有的交换机一起使用。它在整个谷歌数据中心都得到了部署和应用,它实现了更好的负载均衡、更低的丢包率以及更小的应用延迟。作者也将代码进行了开源。
目前最广泛使用的数据中心网络中跨多条路径传播流量的标准负载平衡机制是ECMP(Equal Cost Multi-Path)和WCMP(Weighted Cost Multi-Path)。当开启ECMP功能时,便可同时利用多条路径,实现基于流的负载均衡;WCMP基于路径权重,根据路径的权重分配流量,权重大的路径分配的流量更多。
但是这样简单的机制用于数据中心也是有一些缺点的。由于数据中心流量通常是重尾的,其中少量长流贡献了所有流量的重要部分。因此,一些长流可能会在某些路径上发生冲突,从而造成长期的拥塞,而其他路径则未得到充分利用。但ECMP不会产生平衡的负载,并会加剧拥塞热点。因此作者希望利用现有的传输来识别正在经历拥塞且需要重新路由的流,以此降低网络中的热点,并降低RPC的延迟。
这是第一篇报告数据中心链路利用率不平衡的论文。作者定义了LI(Load Imbalance)的概念。LI是交换机上行链路的最大利用率和最小利用率的差值,代表了链路不平衡指标。作者希望拥塞链路上的一些流可以转移到具有空闲带宽的链路上。
二、PLB设计
PLB需要两个机制:(1)检测主机处的拥塞或链路故障的机制,以及(2)端主机重新路由特定流的方法。PLB在TCP协议和Google的传输协议Pony Express上都进行了实现,均接近50行代码,拥塞检测算法和调度算法伪代码如下图。


首先,发送方主机通过传输检测到连接正处于拥塞状态。PLB-TCP发送方使用一个简单的类似DCTCP的启发式算法来检测连接是否拥塞。发送方计算每次往返过程中带有CE拥塞标记的数据包的分数。当这个分数大于一个常数,那么这个轮是拥塞的。在经历N个连续拥塞轮后,将这个流标记为拥塞。然后PLB通过为后续传出数据包分配一个新的随机生成的流标签,来重新建立连接,当发生重传超时(RTO)时,PLB也会重新建立路径。当流重新开始传输时,没有数据包传输,因此路径更改也不会导致重新排序。
PLB以FlowBender的早期工作为基础,提出了两个改进:①当FlowBender需要过载VLAN标记,这意味着VLAN不再可以自由使用,并且限制了可能受到影响的网络路径的长度。PLB则改为使用IPv6流标签。它允许主机在可用路径集中随机更改流的路径,而无需应用程序参与。②FlowBender只是在出现拥塞时移动连接,PLB则是等到流变为空闲后再重新指定路径,以最小化由于数据包重新排序而导致的传输交互。
PLB的特点是对于减少小型RPC的尾部延迟是有益的。由于发送小RPC的连接经常空闲,PLB倾向于将它们从由重流或大RPC的队列的路径上移开。其次PLB和拥塞控制具有时间尺度分离的特点,这意味着PLB等待拥塞控制动作并降低发送速率,当拥塞控制不能调整时,PLB触发重路由。作者把PLB与热扩散过程联系起来。其中拥塞驱动了流的移动。拥堵越严重,流的流动就越频繁。
三、实验部分
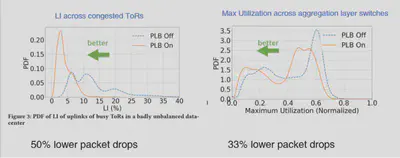
PLB在交换机和应用程序之间均能产生增益。先来看交换机层面数据:作者使用全局遥测监控来获取每个交换机端口的数据,计数器每30s统计一次,同时记录由于输出缓冲区溢出而转发的字节数和丢弃的数据包数。下图左侧代表ToR交换机,蓝线黄线代表PLB部署前后LI指标。在PLB启用之后,负载更加均匀地分布,第50和99百分位数LI降低了70%,明显向较低LI转变。ToR的平均LI从13%下降到4.5%,显著的利用率下降被转换为在该交换机处的分组丢弃降低约50%。
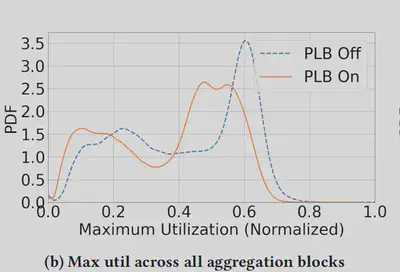
下图右侧展示了数据中心网络中所有聚集层交换机的上行链路之间的最大利用率的前后分布。最大利用率捕获了最繁忙端口交换机可用的空间,随着交换机的最大利用率下降,分布图向左移动,并且图在尾部周围变得更加平坦,这增加了瞬态突发的空间。从而将最大利用率峰值从0.6移到0.5。这些示例表明PLB在最需要的地方(即网络热点)提供了显著帮助。转化为丢包率下降了33% 。
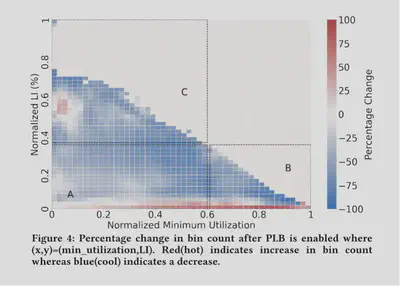
作者希望评估PLB对利用率和负载不平衡的不同组合的影响,接下来作者研究整个Google车队的ToR交换机上行链路。在如此大的运行规模下,整个车队的ToR交换机涵盖了一系列具有不同负载不平衡状态的利用率水平。对于车队中的每个ToR交换机,我们从PLB部署前后两天的测量中收集以下两个指标:LI和最小端口利用率。最小端口利用率与LI反映出ToR上行链路端口的利用率范围。
作者分别计算了部署之前和之后的数据的质量分布变化图,并对样本进行一化处理,其中横纵坐标对应于最小利用率和LI。图颜色反映了启用PLB时所经历的百分比变化。红色表示计数增加,而蓝色表示计数减少。LI接近于0的红色区域表明,在部署PLB后,更多的质量移动到该区域,蓝色阴影显示的高LI区域的质量相应减少,因此PLB更好地实现了负载均衡。
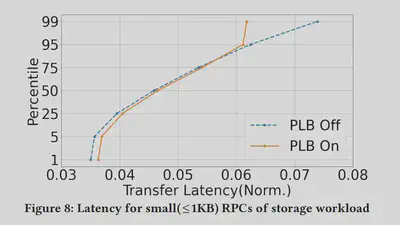
PLB在应用程序上获得的增益体现在两个代表性工作:使用TCP的存储服务和使用Pony Express的分布式文件系统上。存储服务(TCP):存储占Google数据中心流量的大部分。许多应用程序都使用它通过TCP上的RPC进行读写操作。托管这些存储服务器的ToR很容易由于快速的工作负载变化而成为热点。我们研究了小型和大型RPC的网络传输延迟。数据从车队遥测系统中采样,作者测量从第一个字节离开发送方到收到ACK的传输延迟。
作者比较了一个数据中心的存储服务器在PLB部署前后7天的RPC传输延迟变化,在这段期间,整体工作量没有较大改变。下图显示了存储工作负载的小RPC对传输延迟的影响。它们的延迟由物理传播延迟限定下限。可以看到第99百分位数下降了大约20%,而第25百分位数略有上升。说明PLB将更多的流量推向利用率较低的链路,这意味着在较低的百分位数处传输延迟略有增加。
分布式文件系统(Pony Express):下图看到的是低延迟文件系统的截止日期超过率分布。应用对尾部延迟敏感:未能在截止日期之前完成的事务将被取消,并且促使更昂贵的恢复。PLB将该应用程序的中值错误率降低了约66%。
四、总结
PLB是实现数据中心链路级负载平衡的一种简单而有效的方案,它通过google 数据中心网络完全部署,并产生了显著的收益。PLB是一种简单的机制,并很好地结合了交换机端口之间的异构性,传输协议和拓扑结构。论文中第5节,还有很多PLB与其他机制的更有趣的交互。一些未来的工作包括PLB的理论建模,以及与流量工程的紧密结合,以降低其最终的复杂性。
五、思考
首先像PLB这种简单而通用的解决方案总是具有强大的价值增益,因为它结合了低成本和广泛的适用性。其次PLB将传输拥塞作为一个整体进行考虑,不仅仅是基于端到端的检测,而将中间的交换机等都包含在内,是更全面而合理的。