SIGCOMM22 论文分享 | Cebinae: Scalable ln-network Fairness Augmentation

今天给大家介绍的论文发表在SIGCOMM22会议上,作者团队来自宾夕法尼亚大学。本文提出了Cebinae,这是一种用惩罚超过其最大最小公平份额的流量来增强现有主机网络的公平性。Cebinae将拥塞控制算法作为黑盒,对其进行兼容,可部署在商用可编程交换机上。通过实验发现,在网络带宽分配角度,Cebinae的表现优于其他实现公平性的算法。
研究动机
对于像互联网和云公共网络,终端主机应用程序可以使用他们希望的任何拥塞控制协议。然而不同的网络状态(RTT)和拥塞控制协议使用的不同都会导致不公平的带宽分配。因此随着时间的推移,网络的异构性也会急剧增加,从而造成更多不公平分配。
从概念上讲,公平的排队通过将每个流分配给一个独立的队列,并以每位循环顺序为每个流提供服务。为了模拟公平的排队调度,现有方法准确性仍然需要独占使用许多优先级和对每个流的可用缓冲区数量的限制,这两个限制随着流计数、RTT和突发性的增加而变得更加严格。因此现有的解决方案仍然难以在有限的硬件资源下拓展到公共网络,作者指出困难的来源是由于现有的方法试图跟踪并调度每一个流。
Cebinae机制没有在每个时间点进行字节级或包级调度,因为这对于公平的全局收敛是过度的。网络将带宽从满足/超过其公平份额的流重新分配给不满足的流就足够了。这种简化能够以最小的资源(瓶颈和非瓶颈流二分类问题,仅需一个额外的队列优先级)对高级调度逻辑进行非常有效的近似,并大大提高了可扩展性。
关键技术
首先本文从最大-最小公平性的角度出发,对瓶颈链路和瓶颈流的进行了判定。具体而言,如下图所示:
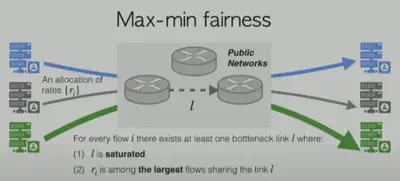
每条链路都可以确定一组瓶颈流集合。首先,如果该链路不是饱和的,那么该链路上的所有流都可以继续增加其发送速率,因此它们不是瓶颈流;其次如果链路是饱和的,那么只要在该链路上发送速率最大的流便被认为是瓶颈流,这是因为发送速率最大的流占用了绝大部分带宽,通过对其进行相关处理,便可以改善不公平分配的情况;否则便不是瓶颈流。
现有方法对于瓶颈流的处理大多采用的是限速操作,只有当链路总需求量低于自身承载能力时,限速才会被解除。然后这种原始的处理方式有一个缺点就是无法使不公平的分配变得公平,如下图所示:
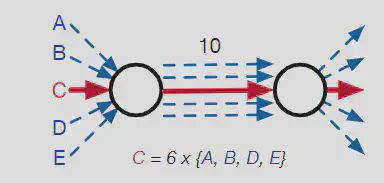
当C流在10容量的链路中获得6容量带宽时,由于只对瓶颈流C进行限速操作,ABDE便会平均分配剩余4容量的带宽,然而这样的分配并不是公平的,然后限速操作并不能让这样不公平的分配变得公平。
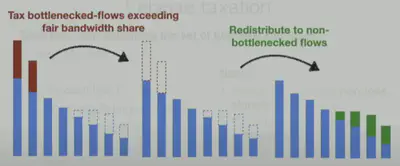
不同于之前的限速操作,Cebinae直接对瓶颈流C进行征税操作,然后将征得的带宽税分配到ABDE,经过数次的征税操作之后,不公平的分配可以变得公平。下图说明了对超过公平份额的流进行征税和再分配的过程:
Cebinae每个路由器的架构如图所示:(a)正常运行期间(b)控制平面重构期间
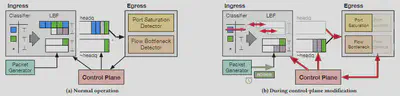
每个路由器包含三个组件:
出口管道流速率缓存,它以细粒度跟踪端口饱和度和瓶颈流状态。
入口管道流调度器,它向瓶颈流输入延迟/损失,以限制和重新分配它们的带宽。
低延迟控制平面代理,它记录流量并动态调整瓶颈流成员度和发送速率限制。
从图中可以看到出口处有两个探测器:端口饱和度探测器和瓶颈流探测器。
为了准确地确定端口饱和度,Cebinae在出口管道上跟踪利用率,为每个端口维护一个简单的传输字节计数器,作为元素存储在一个寄存器数组中。Cebinae控制平面代理定期对寄存器数组进行采样,并在不重置计数器的情况下,计算与前一次迭代观察到的差异,以找到最后一个间隔期间的利用率。如果利用率高于设定值,则认为该链路已饱和。
如果端口饱和度是正的,那么Cebinae就可以确定哪些流是当前链路的瓶颈。Cebinae通过出口管道来检测这些瓶颈流。其目标是准确地跟踪(a)最大流的大小和(b)任何相似大小的流的id。Cebinae使用了散列映射流表的多个阶段。到达一个阶段的数据包被散列到一个条目,要么增加其字节计数器(如果该条目未使用或是用于数据包的流),要么继续到下一个阶段(如果该条目已经被另一个流使用)。Cebinae查找任何流的最大字节计数器,并声明如果它们的字节计数满足约束条件,则该流为“瓶颈流”。
实验验证
作者分别在交换机和ns3仿真中进行了实验,通过实验发现cebinae可以减轻各种网络中的不公平性。
下图显示了对于16个TCP Vegas流(0-15)和一个NewReno流(16),在分别使用FIFO和Cebinae在100 Mbps瓶颈链路上竞争的情况。Cebinae在几乎不影响效率的情况下,将不公平分配转向公平。
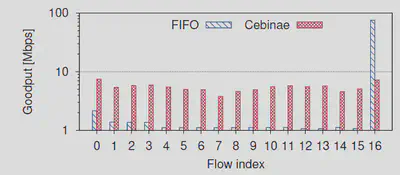
当16个Vegas流(基于延迟)与1个NewReno流(基于损耗)在100 Mbps链路上竞争时,每个流具有相等的RTT和需求。对于FIFO,单个NewReno流占用了大约80%的带宽。Cebinae通过重新分配NewReno流的带宽并允许其余流增加其份额来提高公平性。
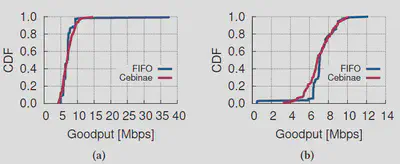
图a说明了一个类似的情况,即128个NewReno流在1 Gbps链路上与2个BBR流竞争,RTT和需求相等。Cebine对BBR流要求的过度带宽征税,并将JFI从0.774提高到0.936。
另一种情况是,128个NewReno流在1Gbps链路上与4个Vegas流竞争,其性能需求和RTT分别为100ms和64ms。虽然最初的JFI提供了看似较高的值(0.956),但这是由于大多数NewReno流量(及其主要流量)得到了相对公平的分配。这掩盖了对4个拉斯维加斯流量的不公平分配,如图b中详细的goodput分布所示。Cebinae减轻了4个Vegas流的饥饿现象。
个人总结
Cebinae将拥塞算法视为黑盒,通过征税的的手段近似地实现了最大最小公平,解决了原始最大最小公平无法使不公平分配公平化的弊端,虽然没有从理论上证明Cebinae收敛到最大最小公平,但是它能够利用更少的资源减轻不公平现象。
解决某类问题,可以将其映射到实际生活中,通过实际生活已有的模型或者方法对问题进行抽象。